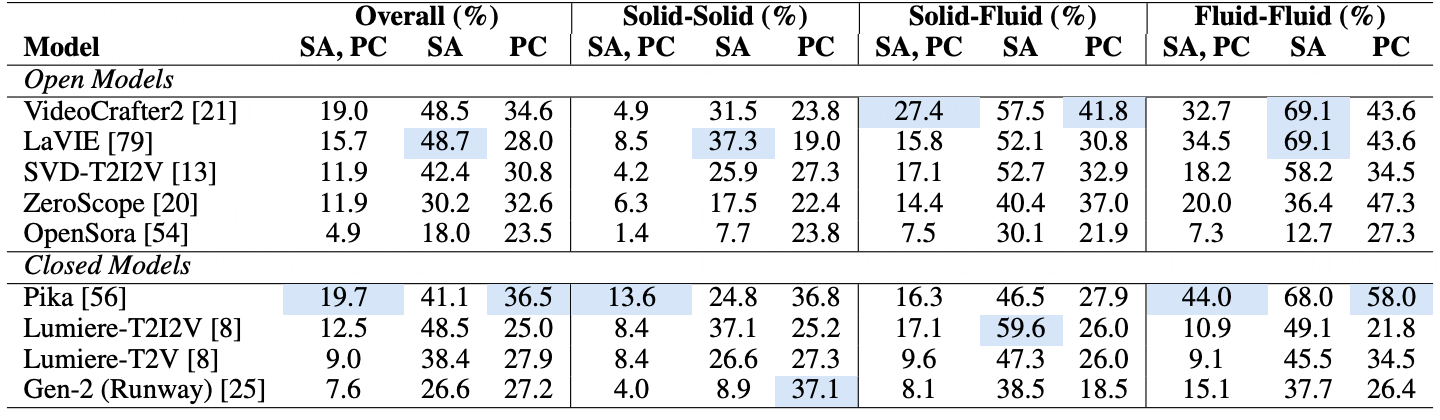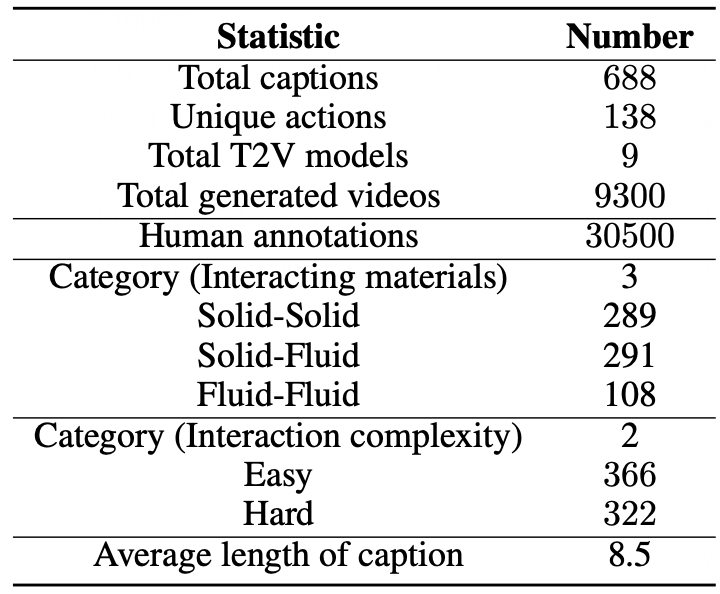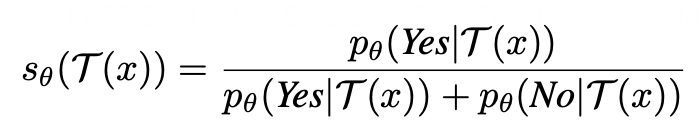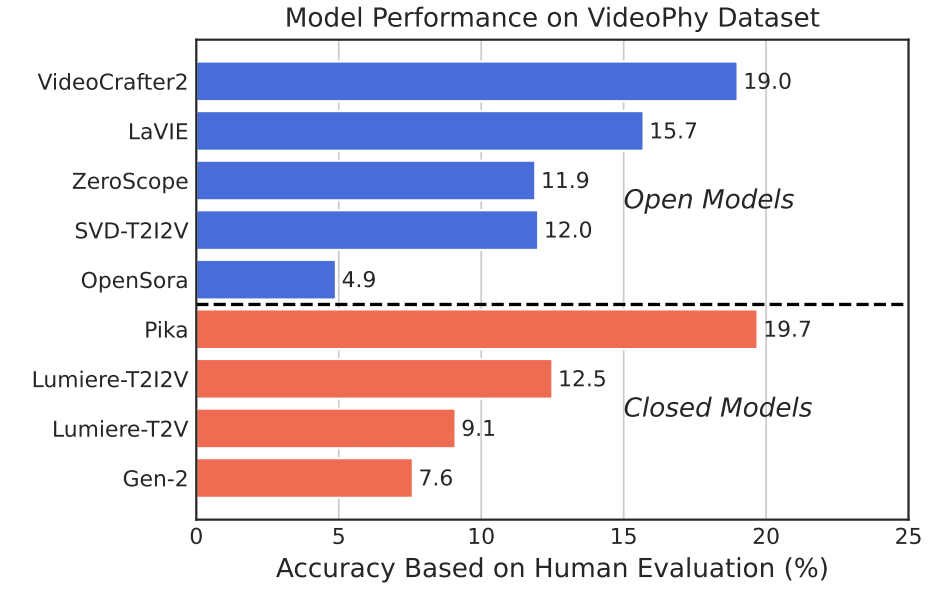

Human evaluation results on VideoPhy. We abbreviate semantic adherence as SA, physical commonsense as PC. SA, PC indicates the percentage of the instances for which SA=1 and PC=1.
Open Models
| # | Model | Source | PC=1 | SA=1 | SA=1, PC=1 |
| 1 | CogVideoX-5B 🥇 | Open | 53 | 63.3 | 39.6 |
| 2 | VideoCrafter2 🥉 | Open | 34.6 | 48.5 | 19.0 |
| 3 | CogVideoX-2B | Open | 34.1 | 47.2 | 18.6 |
| 4 | LaVIE | Open | 28.0 | 48.7 | 15.7 |
| 5 | SVD-T2I2V | Open | 30.8 | 42.4 | 11.9 |
| 6 | ZeroScope | Open | 32.6 | 30.2 | 11.9 |
| 7 | OpenSora | Open | 23.5 | 18.0 | 4.9 |
Closed Models
| # | Model | Source | PC=1 | SA=1 | SA=1, PC=1 |
| 1 | Pika 🥈 | Closed | 36.5 | 41.1 | 19.7 |
| 2 | Luma Dream Machine | Closed | 21.8 | 61.9 | 13.6 |
| 3 | Lumiere-T2I2V | Closed | 25.0 | 48.5 | 12.5 |
| 4 | Lumiere-T2V | Closed | 27.9 | 38.4 | 9.0 |
| 5 | Gen-2 (Runway) | Closed | 27.2 | 26.6 | 7.6 |
🚨 To submit your results to the leaderboard, please send to this email with your csv with video url and captions from the model builders for human / automatic evaluation.